Assignment 07
FlowVis
- Preliminaries
- Submission
- Loading Vector Field Data
- Direct Visualization
- Geometry-based Visualization
- Experimentation and Report
- Additional Concerns
- Grading
Preliminaries
Vector field data is common in a variety of settings, including scientific simulations for combustion and computational fluid dynamics as well as real world phenomena such as climate and blood flow. The key difference from scalar field data is the need to model, and thus visualize, phenomena that flow. This assignment will explore visualizing vector fields using both direct and geometric techniques.
As in the last two assignments, we will be using both openFrameworks and VTK. But, we will only require the use of VTK for reading vector-value data stored on regular grids.
Submission
For this assignment you will submit one directory that demonstrates the various parts of your assignment, named A07P01. I will expect the following structure, in particular with a CMakeLists.txt that conforms to the ofnode/of examples:
A07P01/
src/*
bin/ <-- Do not include data/*.vti in your git repo; the files are large
CMakeLists.txt
report.YYY
Feel free to include anything needed to run your code (e.g. font files) as well as all associated files for your report.
Loading Vector Field Data
Your process to read vector-valued “image” data will be very similar to reading scalar-valued images. Just as in the past assignments, a vtkXMLImageDataReader will be used to open the file. You can access the size of the image using vtkImageData::GetDimensions(), and this class will also allow you to access the origin and spacing. These units will help you work in the appropriate spatial coordinates. See Assignment 05 for a brief description as well as the examples and documentation for vtkImageData.
To access the vector-valued data, you will need to access a different vtkDataArray that you previously were. This can be accessed using GetVectors(), with a call such as this:
vtkSmartPointer<vtkDataArray> vectors = image->GetPointData()->GetVectors();For vector-valued data array, each tuple will now store more than one value, and thus we will not call GetTuple1() (the “1” assumes one value) but instead we will use the more general form of GetTuple(), which expects an array of doubles. You can discover the size of this array – how many components each vector has – using vtkDataArray::GetNumberOfComponents(). Together, this means you can access the vector at each position using a loop such as:
double* vec = new double[vectors->GetNumberOfComponents()];
for (int i=0; i<dims[0]*dims[1]; i++) {
vectors->GetTuple(i, vec);
//vec[0] is the x-component of the vector
//vec[1] is the y-component of the vector
//...
}
delete[] vec;Assuming that in the above dims[0] is the \(x\)-resolution and dims[1] is the \(y\)-resolution. For our purposes, we will only be working with two-dimensional vector fields, and it will be appropriate to ignore all components except for the \(x\)- and \(y\)-component.
openFrameworks provides a number of utility classes for storing and manipulating vectors in low dimensions. These are handy because they provide use arithmetic operations, such as scalar-vector multiplication, vector-vector addition, cross products, dot products, and vector magnitude. For this assignment, I recommend that you convert the VTK-formatted data directly into ofVec2f elements. One simple way to do this is to use the following:
ofVec2f* data = new ofVec2f*[dims[0]*dims[1]];
double* vec = new double[vectors->GetNumberOfComponents()];
for (int i=0; i<dims[0]*dims[1]; i++) {
vectors->GetTuple(i, vec);
//vec[0] is the x-component of the vector
data[i][0] = vec[0];
//vec[1] is the y-component of the vector
data[i][1] = vec[1];
}
delete[] vec;Note that your code may benefit from storing the above array of ofVec2f as a 2d array, for clearer code when we get to the next portions of the assignment. The above code example is just a simple, bare bones example of converting from the vtkDataArray to a more openFrameworks-friendly data structure.
Direct Visualization
For this assignment, I recommend creating a class vectorField that encapsulates the functionality for loading and converting vector field data from .vti files to an ofVec2f data. This class can also maintain the origin and spacing of the underlying field, and thus the true geometric extents. Your visualization should first support displaying an image of the magnitude of the vector field at every position, using color-coding. ofVec2f::length() will be handy for computing the scalar magnitude. Your visualization must include a color legend, but can be color-coded in whatever way you choose. Please discuss this choice in your report. A greyscale encoding of the 3cylflow data looks as follows:

You will also need to implement a function that interpolates the vector values at an arbitrary \((x,y)\) position within the extents of the data. In my implementation, this function had the following signature:
ofVec2f interpolate(const ofVec2f& pos);interpolate() computes the associated two-dimensional vector for a given position pos. Since all data is on gridded images, you will use bilinear interpolation of the four nearest data values for this task (see Lecture 17).
This function will be necessary because your visualization should allow the user to resize the color-coded image on the screen. A simple version of this will use two sliders that adjust the width and height of the image in pixel coordinates. You should also include some kind of legend that indicates to the user the spatial extents of the domain. Your code must then convert from the pixel coordinates that you specify to the true spatial coordinates of the underlying field, and then resample the image using interpolate(). Note: You are not allowed to use ofImage::resize() for this task.
Alternatively, you could also consider using the mouse to implement a zoom and pan interface, but please make sure you keep the mapping from any given pixel drawn on the screen to actual \((x,y)\) position available. You will need this for the second portion of the assignment. I do not recommend using the openFrameworks’ EasyCam for this, as the inverse mapping will potentially be tricky to determine.
After implementing this portion of the assignment, take a small break to explore some of the provided datasets (data07.zip). You may also want to load them in ParaView to compare. Can you make any conclusions about the behavior of the flow field at this point? Please as describe how you indicated to the user the \((x,y)\) space of the data.
Geometry-based Visualization
After getting your basic color mapped visualization of the magnitude implemented, your next task is to create an interface for the user to draw streamlines on the flow field. To do this, you will implement the Runge-Kutta 4 method as described in class (see Lecture 23 and Lecture 24). On option here is to take advantage of openFrameworks’ class for drawing polylines (ofPolyline) for storing these, so that you can simply call ofPolyline::draw() to draw them. My signature for this function looks like this:
ofPolyline rk4_integrate(const ofVec2f& start, double dt, int num_steps);Note that in the above, I take a starting position start as well as two parameters you using expose to the user: (1) the amount of time each step takes ,dt , and the number of steps you will integrate, num_steps.
Your interface for streamlines must allow the user to specify both numeric parameters and allow them to specify the starting position by clicking on the screen and overlaying the streamline on top of the color encoded velocity magnitude field. Thus, you will have to again convert from the pixel-based position the user clicks on as a seed position to units associated with the vector field’s extent. Within your integrator, you will have to query for the vector values at arbitrary positions using your interpolate() function. rk4_integrate_streamline() must then at least support integrating in the forward direction. A successful base implementation, encoding the streamlines as red polylines, might look like the following:
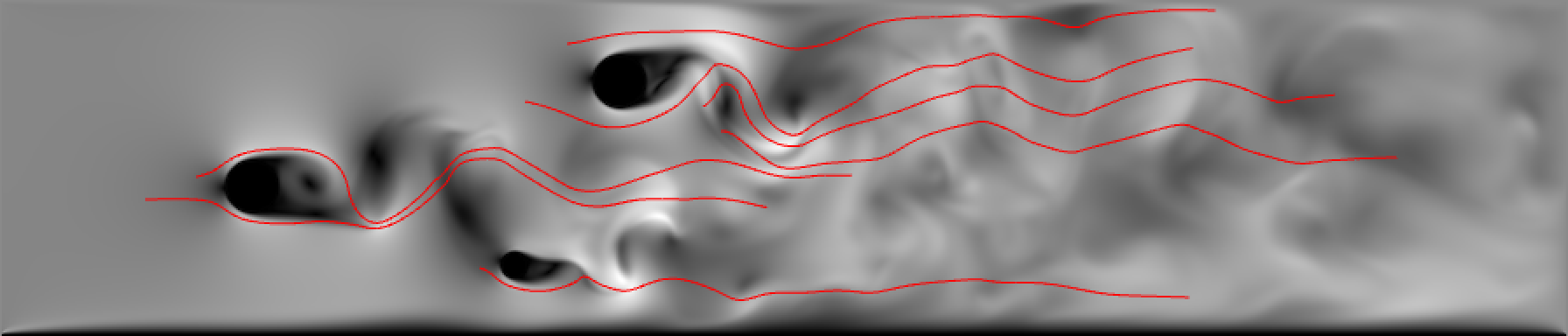
Experimentation and Report
After completing both parts of the assignment, pick two of the provided datasets (data07.zip) and try visualizing them using all features of your tool. What interesting features do you discover? How do they compare? Include screenshots.
In your report, evaluate and describe the use of direct encoding of the velocity magnitude vs. geometric encoding using streamlines. What features can you see using each? What aspects are hard to interpret using each individually?
Finally, describe any design considerations and choices that you made, including how you configured your interface and chose to solve the problem. While there is no need to sketch in advance, you may want to include such discussions if you deviated significantly.
Additional Concerns
You may want to consider exposing a number of additional features to the user that could improve their ability to understand this data. For example, consider allowing the user to encode other characteristics of the field with different color maps. You could also consider rendering streamlines using more sophisticated techniques that simply drawing ofPolyline’s, that can perhaps encode magnitude, orientation, or time of integration using color, thickness, or texture. You may also want to compare other features of the integrator (e.g. forward vs. backward integration) or other, simply integrators (e.g. Euler). Finally, you might also consider different ways to seed streamlines other than user clicks.
Grading
My expectation is that you will submit one new folder in your git repository. This folder should contain everything necessary to compile and run your program as described above. This folder should also contain a report document in a format of your choosing.
I will specifically weigh the following parts of the assignment as:
- 30% Completing the interface for displaying the velocity magnitude and resizing
- 30% Completing the interface for integrating streamlines
- 40% Completing the report and experimentation.
These percentages will be scaled to the total value of this assignment for your final grade (8%). For each of the coding parts, I will specifically check that you’ve read in the data correctly and processed it as described above. I will also check for coding style, commenting, and organization where appropriate.
Extra credit will be awarded for implementing features that significantly go beyond the requirements.